
در ادامه مباحث کاربردهای هوش مصنوعی در زمینه خدمات و تعامل هوشمند با مشتریان، در این بخش، به تحلیل احساسات کاربران با استفاده از هوش مصنوعی میپردازیم. در ادامه، نیاز شرکتهای مخابراتی در زمینه تحلیل احساسات مبتنی بر متن و روش مرسوم برای انجام آن ارائه میشود.
یکی از نیازهای شرکتهای مخابراتی دانستن احساسات و نظرات کاربران درباره موضوعات خاصی مانند: محصولات، خدمات و برند آنها است؛ به عنوان مثال، ارزیابی ادراک عمومی از ۵G از طریق تحلیل احساسات کاربران شبکههای اجتماعی.
تحلیل احساسات کاربران با استفاده از هوش مصنوعی روشی است که میتواند به طور موثری به این نیاز پاسخ دهد؛ به طوریکه شرکتها با به دست آوردن این دانش و آگاهی میتوانند مشتریان خود را بهتر بشناسند، شهرت برند خود را مدیریت کنند، محصولات و خدمات خود را بهبود بخشند، رقابتی بمانند و تصمیمات استراتژیک تجاری بگیرند. به عنوان مثال، اگر تجزیه و تحلیل احساسات پاسخ مثبت مشتریان به یک ویژگی جدید را نشان دهد، شرکت ممکن است تصمیم بگیرد که روی آن ویژگی سرمایهگذاری بیشتری داشته باشد.
تجزیه و تحلیل احساسات که به عنوان عقیدهکاوی نیز شناخته میشود استفاده از پردازش زبان طبیعی (NLP)، زبانشناسی محاسباتی و تحلیل متن برای کشف و استخراج سیستماتیک و خودکار احساس موجود در متن است. یکی از رویکردهای مرسوم برای انجام این کار یادگیری ماشین/یادگیری عمیق است که با استفاده از آن میتوانیم حجم عظیمی از دادهها را مورد پردازش قرار دهیم. مدلهای یادگیری ماشین/یادگیری عمیق میتوانند الگوهای موجود در دادههای موجود را یاد بگیرند و سپس این مدلها میتوانند بر روی متون جدید تحلیل احساس انجام دهند، به طوریکه میتوانند مشخص کنند احساس/عقیده/نظر بیان شده توسط یک کاربر مثبت، منفی و یا خنثی است. برای جمعآوری داده، شبکههای اجتماعی یکی از منابع مهم داده محسوب میشوند. به عنوان مثال، تقریبا هر شرکت بزرگی یک حساب Twitter برای پیگیری نظرات مشتریان در مورد خدمات یا محصولات خود دارد.
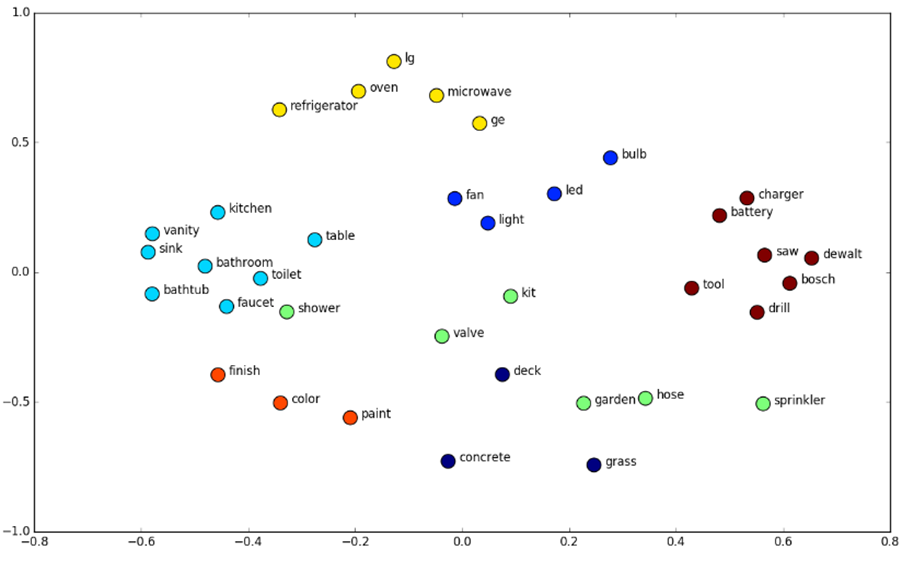
در بخش “هوش مصنوعی و اهمیت آن در صنعت تلکام” گفته شد آنچه که ماشین را قادر به انجام تواناییهای انسان یا فراتر از آن میسازد، مدلها و الگوریتمهای ریاضی هستند که این مدلها و الگوریتمها ورودی را به صورت عدد قبول میکنند. بنابراین، این سوال ممکن است مطرح شود که به عنوان مثال نظر یک کاربر درباره یک محصول که به صورت متن است، چگونه به صورت عددی بیان میشود. برای انجام این کار، ابتدا پردازشهای اولیه (حذف علائم نگارشی، کوچکسازی حروف، حذف ایست واژهها، واحدسازی، ریشهیابی و …) بر روی متن انجام میشود. با انجام این پردازش، متن از زبانطبیعی به فرمت قابل خواندن توسط ماشین تبدیل میشود. سپس از تعبیهسازی واژه(Word Embedding) برای بردن واژهها به فضای برداری(نمایش آنها به صورت بردارهای عددی) استفاده میشود. این تعبیهسازی به گونهای است که واژههایی که از نظر معنایی مشابه هستند در فضای برداری نیز به هم نزدیکتر هستند. با استفاده از این روش میتوان معنای کلمات را تقریب زد و یک بازنمایی از آنها در فضای با ابعاد پایین به دست آورد. شکل زیر نتیجه تعبیهسازی واژهها را نشان میدهد. همانطور که مشاهده میشود کلماتی که معنای مشابهی دارند در فضای برداری نیز به یک دیگر نزدیکتر هستند. اکنون با به دست آوردن یک بازنمایی از واژهها به صورت بردارهای عددی میتوان آنها را به عنوان ورودی به مدلهای یادگیری ماشین/یادگیری عمیق داد؛ سپس باید بقیه مراحل مربوط به آموزش مدل، ارزیابی مدل و پیشبینی احساس انجام شود.
تعبیه واژه ها
سیدحسین حسینی فخر
منابع:
[۲] Customers’ Opinions on Mobile Telecommunication Services in Malaysia using Sentiment Analysis, International Journal of Advanced Computer Science and Applications, 2021.
[۳] Assessing the Public Perception of the Fifth Generation of Mobile Communication (5G) by Sentiment Analysis of Twitter Users, Journal of Modern Research in Decision Making, 2022
[۴] devopedia.org/word-embedding
[۵] Twitter Sentiment Analysis of Real-Time Customer Experience Feedback for Predicting Growth of Indian Telecom Companies, 2018 4th International Conference on Computing Sciences (ICCS)